
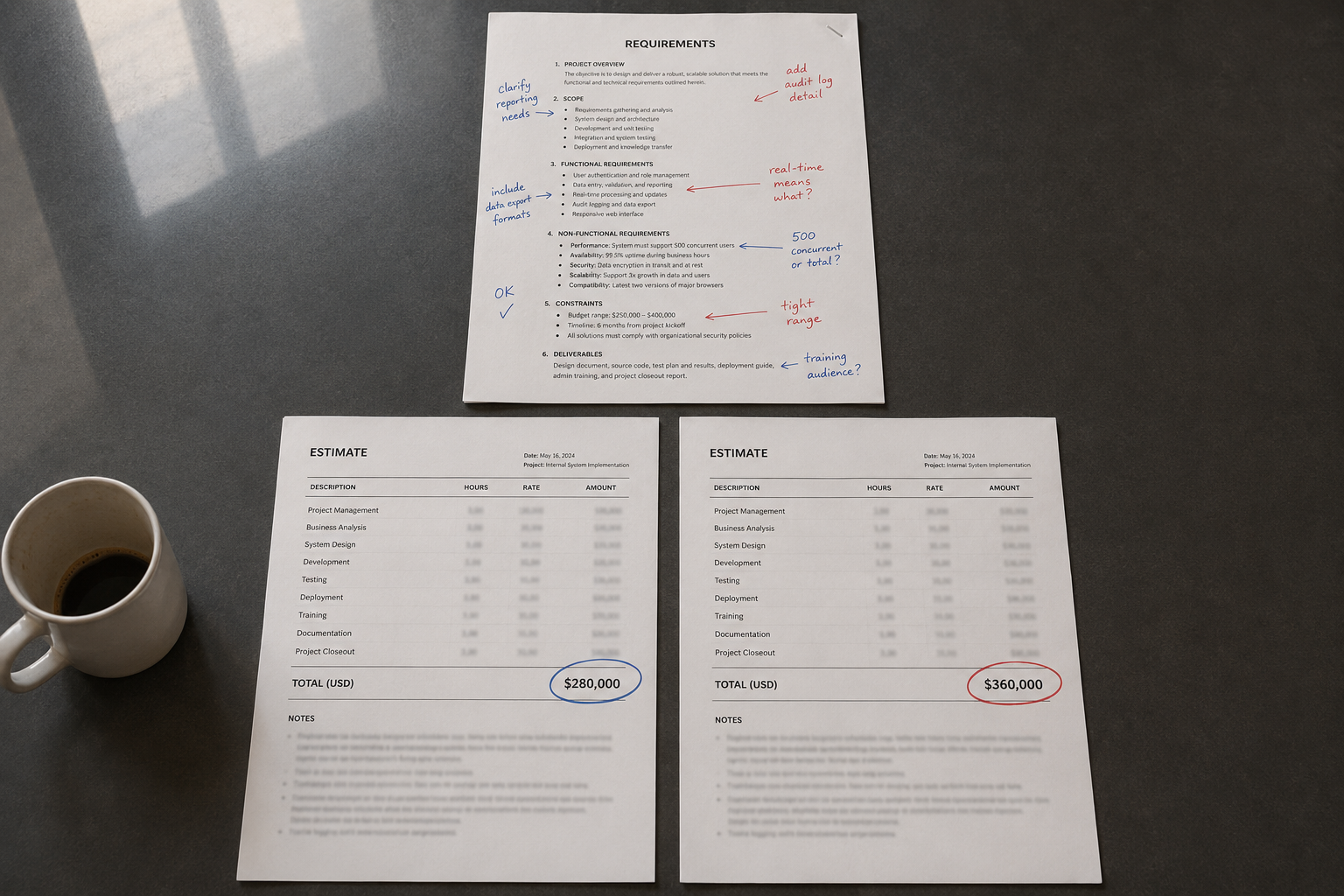


Ask two developers to estimate the same requirements document. Do it blind, without comparing notes first. You'll probably get numbers that differ by 20 to 40 percent. Sometimes more.
This isn't a skills problem. It happens in teams with experienced engineers, clear briefs, and years of delivery behind them. It happens on the second estimate of a deal type you've done a dozen times.
The easy read is that one person padded more. That's estimator variance, and the usual explanation for it is wrong.
"They padded differently" is the wrong diagnosis
Padding is usually visible in review if you look for it. The causes worth finding are structural: they compound quietly, they survive calibration sessions, and they don't go away when you hire more experienced people.
There are three.
Contingency stacking. A developer adds a buffer to anything that feels uncertain. The solution architect reviews the estimate and adds a contingency line for integration risk. The head of professional services adds a margin before it goes out. Each decision is reasonable in isolation. Stacked, they produce a number nobody can fully explain, carrying three layers of risk coverage with some of it definitely overlapping.
The buyer sees a total. Nobody inside the deal can tell you where the risk actually lives, or whether the contingency on line 7 is already covered by the padding in tasks 12 through 18.
Contingency stays. What changes is deciding once, as a practice, where in the deal it belongs, how it's calculated, and who owns it. That's a policy, not a conversation.
Recency bias. Whoever is running the estimate is doing it from somewhere. If they're currently firefighting a delivery on a similar project that went sideways, their estimate for the new one will be higher. Their experience is real data. But it's data about their current situation, not this scope. If the bench is stretched and every active project is under-resourced, timeline estimates will creep upward.
This shows up as a scope judgment. There's no column for "current project pain factor." It looks like a number and it's partly a mood.
Requirement interpretation. Requirements are rarely complete. Different engineers fill the gaps differently based on experience, and the gap-filling almost never gets written down. One reads "API integration" and assumes a simple outbound call. Another assumes a full authentication handshake, error handling, and retry logic. Neither is wrong given what the brief says. But they've priced different pieces of work.
Capture assumptions during estimation and share them with the buyer. That keeps everyone aligned on what was actually priced, and it makes change requests defensible later.
The fix is not a meeting
Once you understand where the spread comes from, the calibration session looks like what it is: a way to show the symptom without touching the cause.
You can spend an afternoon aligning two engineers on what the integration scope includes for this specific deal. That alignment exists until the next deal. The next person who joins the team starts from scratch. The next requirement that doesn't fit the existing template produces the same spread.
The permanent fix is making implicit decisions explicit and shared before anyone opens a blank estimate. One policy for where contingency lives and who owns it. One place where scope assumptions get declared before estimating starts, not discovered mid-estimate.
Estii's rate cards lock the price and margin behind every role in one governed place, so the number behind "Senior Developer" is settled before the first estimate opens. The remaining disagreement (about how many days, which roles, what risk) is the only disagreement worth having.
The data that actually calibrates a team
Structural fixes reduce variance on the next deal. What calibrates a team over time is feedback.
The question worth being able to answer before any estimate goes out: what was our average variance on this type of requirement across the last three similar projects? Whether the deal came in on budget won't tell you; that number is usually obscured by scope changes and commercial adjustments made after signature. The useful questions are harder: what did we estimate, what did we actually resource, how much did the scope change in delivery, and which assumptions did we capture versus miss?
When an engineer estimating an API integration knows their team has consistently run 20 percent over on integrations of this type, they have something real to calibrate against. When they know the last three similar projects all had scope changes that traced back to assumptions nobody wrote down before close, they know which questions to ask the buyer before this estimate goes out.
Most practices don't have this data in a usable form. The estimate lives in a spreadsheet. Delivery data lives in a project management tool. Scope changes live in email threads. Assumptions, if anyone captured them, live in a document nobody linked from the estimate. Nobody has ever connected those four things in a way that lets the next estimate learn from the last one.
Recency bias is the informal version of this feedback loop. The developer who just came off a painful delivery is drawing on real information, but it's private, unverified, and not adjusted for what was different about that project. Shared delivery data replaces private pain with a calibrated signal. The pessimistic estimate and the optimistic one start converging, because both engineers are looking at the same history.
The kind of disagreement that's actually useful
Once you remove contingency stacking, recency bias, and unwritten assumptions from a deal review, what's left is an honest disagreement about scope.
One engineer thinks the integration will take three weeks. Another thinks two. That's a real conversation. They're disagreeing about how hard the work is, and if there's delivery data behind them, they're not just arguing from intuition.
Variance that comes from structural ambiguity is noise. Variance that comes from genuine scope uncertainty is information.
Most deal reviews spend their time on noise. Engineers defend their assumptions, the head of professional services tries to find the midpoint, and the number that goes out is a compromise between two privately different interpretations of the same brief.
A 30 percent spread is what you get when each person defines the work themselves. Fix the structure, share the data, and the spread collapses to the cases where the work itself is genuinely uncertain.
Those are the cases worth arguing about.

